| Extract Text |  Download |
Extract Text
Introduction
This program is able to extract the text content of different types of documents. It is based on the technology in the Microsoft Index Server, which uses something called IFilters to index text in files.
Using The Program
The program is very simple to use. It is a command line utility and takes only two parameters. It has to know the file name of the document that you want to extract text from. It also needs the file name of the new file that should hold the extracted text.
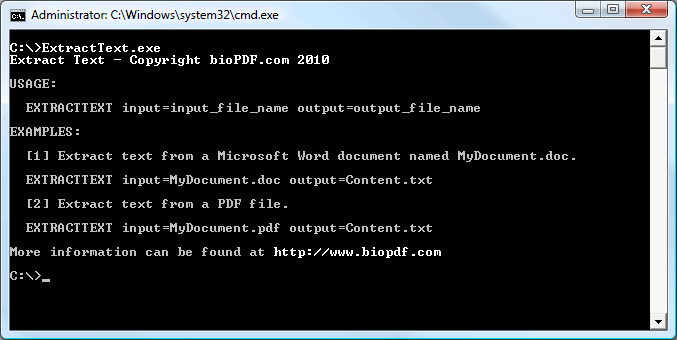
Prerequisites
Before you are able to run the program you need the following installed on your system:
- Microsoft.NET Framework 4.0.
Installation
This program is just a couple of executable files. It doesn't require any installation. You simply unzip the downloaded files and copy them to the folder of your choice.
Extract Text From PDF Documents
The PDF filter DLL needed to extract text from PDF files was included with Adobe Reader 7.0.5 to 9.x. Starting with the release of Adobe Reader 10 also known as Adobe Reader X, this DLL is no longer part of the Adobe Reader installation.
You can still extract text from PDF files if you run Adobe Reader X or another brand of PDF reader. Adobe has a separate download that will install the filter you need. Please follow the link below to get the IFilter from Adobe.
Download Adobe PDF IFilter v6.0
Extract Text From Office Documents
Microsoft offers a filter pack that enables you to extract text from the following file formats: .docx, .docm, .pptx, .pptm, .xlsx, .xlsm, .xlsb, .zip, .one, .vdx, .vsd, .vss, .vst, .vdx, .vsx, and .vtx.
Download Office 2010 the filter pack
Download Office 2007 the filter pack
Version History
2013-01-25 (4.1.0.0)
- Support for both 32 and 64 bit filters.
- Now uses Microsoft.NET 4.0 instead of 2.0.
2012-10-17 (3.0.0.0)
- Improved error handling.
2011-02-15 (2.0.0.0)
- Always runs in x86 mode to support more filters on 64 bit machines.
2010-02-12 (1.0.0.0)
- First release.